Why Your Corporate Data Isn’t Safe in AI (And What to Do About It)

Why Your Chatbot Needs Its Own Home
Today, everything is AI. AI blenders, AI toilet paper, even AI protein. If your product doesn’t have those two letters in its name, it might as well not exist.
But while the world is riding the hype wave, we at Inogile (yes, we used to be the “Starbug guys”) looked under the hood. And I’ll tell you — it’s not always a pretty sight.
Maybe you know me as someone who isn’t afraid to say things straight.
So here’s the hard truth: Your company secrets are most likely serving as training data for Google or OpenAI right now.
Are Today’s Models Secure? Spoiler: No.
When I read Gemini’s Privacy Policy, I nearly choked on my coffee. Google states in black and white: “Do not enter confidential information.” Why? Because a human reviewer can see it, Google uses it for training, and tomorrow your competitor might get it as a response to their prompt.
Similar terms of use apply to the competing ChatGPT, which also states it uses data for machine learning. The good news is you can opt out and disable this feature directly in settings. Whether disabling it actually ensures your data won’t be shared — I’ll leave that for each of you to decide.
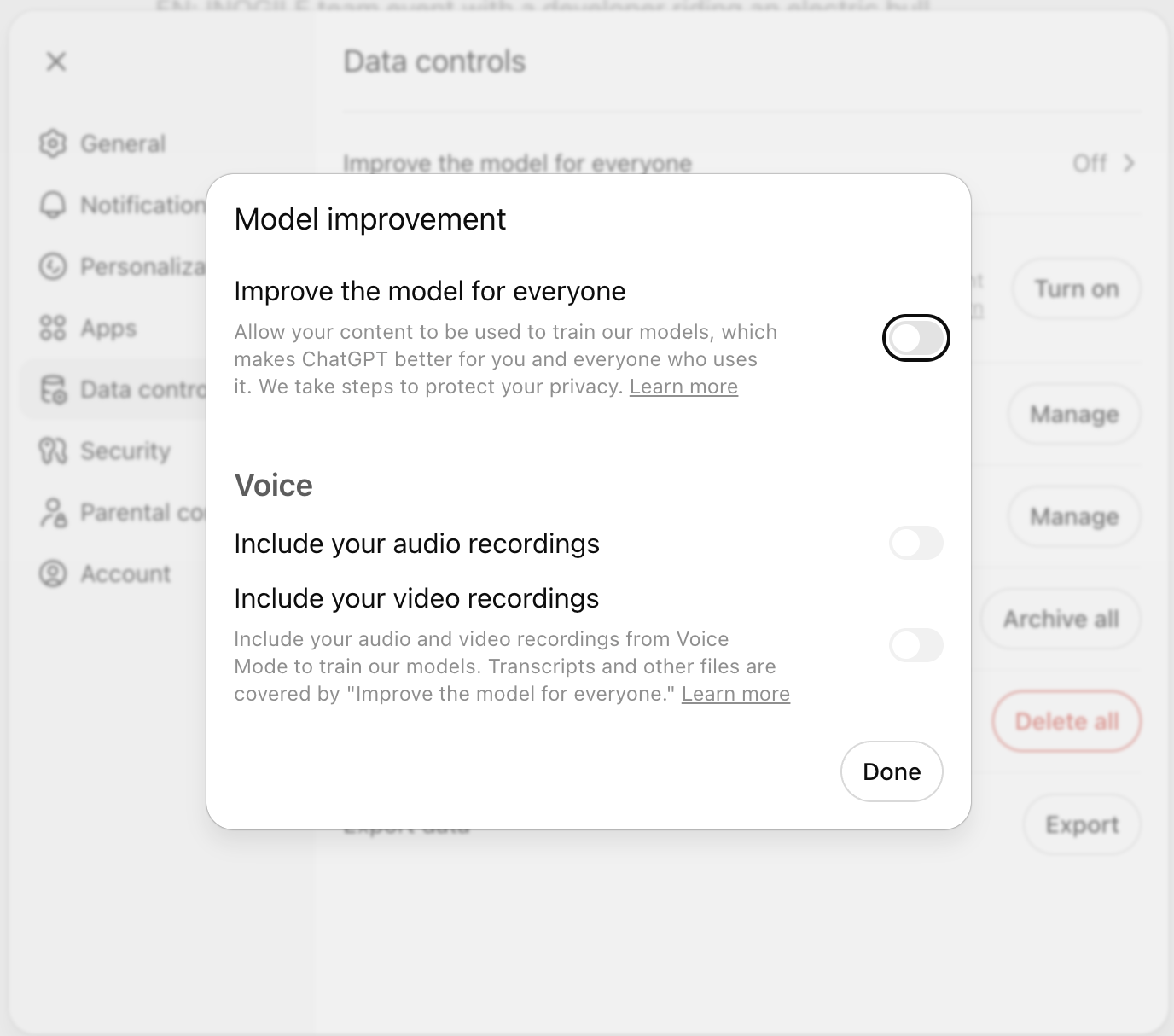
At a minimum, I recommend configuring the following setting in GPT (more for peace of mind regarding security):
Real “Million-Dollar Fuck-Ups”
And this isn’t just theory. We have real cases that cost companies millions:
Samsung (2023)
Samsung Semiconductor employees pasted chip database source code, code for optimizing defective devices, and internal meeting transcripts into ChatGPT — three separate incidents within 20 days. The result? All that data became part of OpenAI’s training dataset. Samsung couldn’t take it back — the data sits on OpenAI’s servers, and by their own admission, they cannot delete it from specific prompts.
Following this incident, Samsung restricted ChatGPT inputs to 1,024 bytes and began developing its own internal AI tool (Gauss). In 2025, they reopened ChatGPT access with new security protocols.
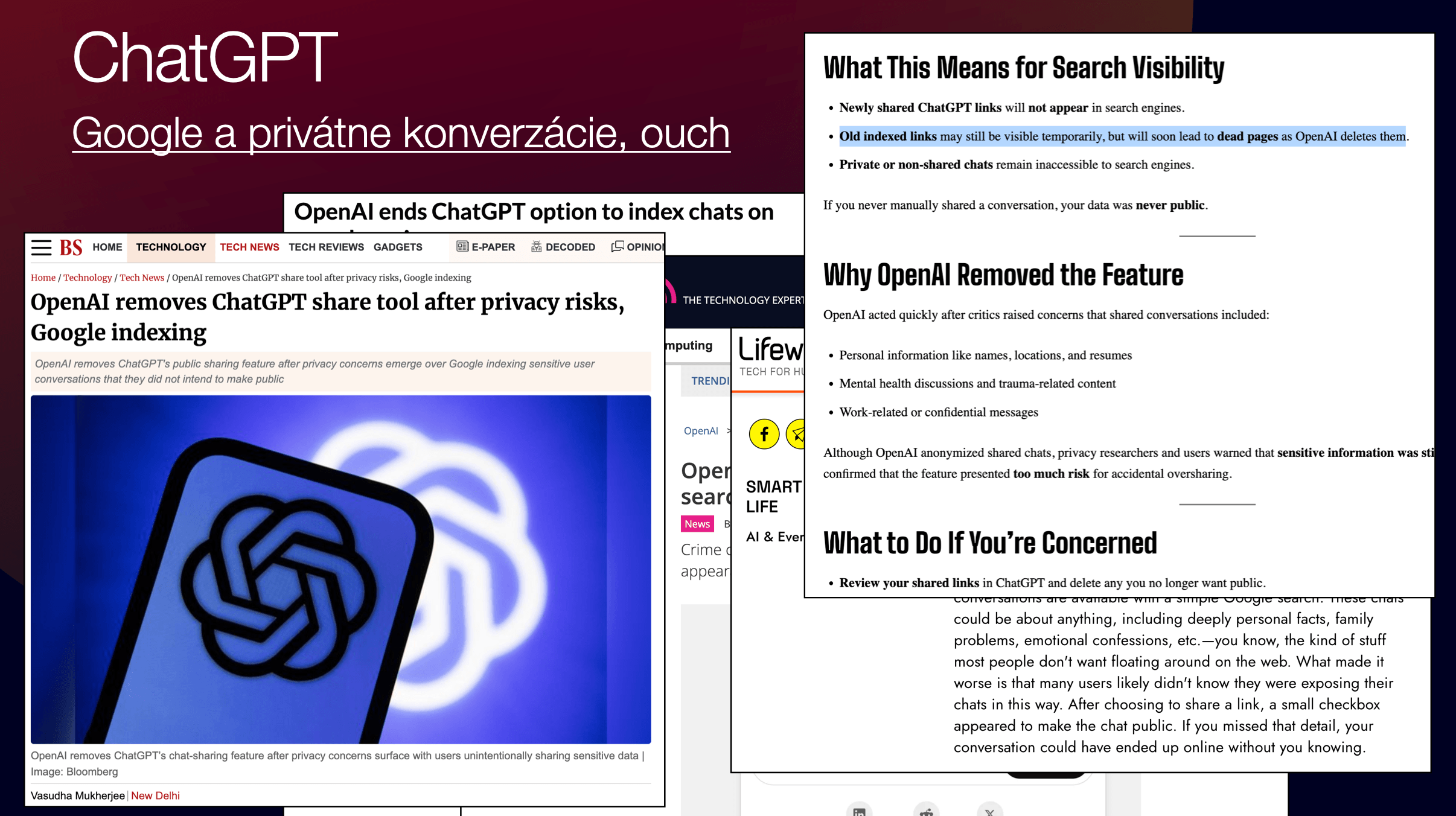
ChatGPT Conversations on Google (2025)
In the summer of 2025, it turned out that shared ChatGPT conversations were being indexed directly in Google Search. All you had to do was type site:chatgpt.com/share into Google, and you could find resumes with full names and phone numbers, corporate strategies, API keys, and even personal confessions.
How did this happen? ChatGPT had a “Share” function with a checkbox “Make this chat discoverable.” The problem was that OpenAI’s robots.txt allowed indexing of these pages, and noindex tags were missing. So, Google did what it always does — it indexed everything it could. An estimated 100,000+ conversations were indexed.
OpenAI eventually removed the feature and asked Google to deindex. But many conversations are still available on Archive.org. Forever.

The Solution? Build Your Own Agent. On Your Own Hardware.
Customers don’t want to hear that their data is “maybe” safe. They want certainty. That’s why at Inogile, we’re pioneering offline AI agents.
What do you need for this?
1. A solid machine: Forget overpriced workstations. The best price-to-performance ratio for running LLMs today is a Mac Mini with Apple Silicon. Thanks to unified memory, it works exceptionally well — GPU and CPU share the same memory space, which is exactly what LLM models need.
2. A player — Ollama: Think of it as Winamp for artificial intelligence. You download a model (e.g., Llama from Meta or Mistral) and run it locally. No internet required. Your data never leaves your building.
3. Python: A bit of coding to tie it all together into a working solution.
The Holy Grail: Teach the Model Your Data
There are several types of model training. One is SFT (Supervised Fine Tuning) — full-scale retraining of the model on your data. It’s powerful but expensive and time-consuming. For many use cases, there’s a simpler path: RAG (Retrieval-Augmented Generation).
RAG is essentially a “question wrapper.” Imagine you have a model that only knows things up to 2023. It’s like a little clueless genius in a box. Ask it about your company, and it knows nothing.
But if you place a RAG layer between you and the AI, it takes your question, appends current data (e.g., your terms and conditions or product catalog), and feeds it to the model with an instruction: “Answer this, but only use this context.”
The result? You have a chatbot that knows your latest products, but your data never leaves the building.
It’s important to know that RAG isn’t magic. The RAG question wrapper also consumes tokens that the model can process. The more data included in the RAG file, the less room the model has for its actual response. For more complex scenarios — large data volumes, complex structures — a company will need full-scale training via SFT.
Personalization: From Senior Executives to Generation Alpha
The beauty of having your own orchestrator (that’s you — like Tony Stark of your AI) is that you can fine-tune behavior:
• Want the AI to respond to a lawyer? It’ll use specialized terminology and precise wording.
• Want a response for a 12-year-old “hobbit” from Generation Alpha? RAG will tell them your product is “OMG literally totally fire.”
Yes, AI likes to “ramble on” because it wants to extract tokens from you (which you pay for in the cloud). But in your own system, you simply tell it: “Be concise and don’t treat me like an idiot.” And it obeys.
The Verdict: Do You Need an IT Company for This?
You might suspect me of narcissism here, but the answer is: yes.
Sure, you can generate a RAG file yourself via ChatGPT (if you don’t mind it learning from you again). But building a robust system where nothing breaks, databases work, and the customer gets real value — that’s a different league.
RAG is a great helper, but it should be seen as an effective productivity tool, not a replacement for a full-fledged AI solution. For more complex scenarios, SFT is essential.
The future isn’t about who has the bigger OpenAI subscription. The future is about who can tame AI, secure it, and make it work on their own data. We at Inogile are already doing this.
Do you have the courage to disconnect from the cloud and truly own your intelligence?
Stop by and we’ll put you to the test.
More articles


INOGILE / Starbug is expanding into the Czech Republic
Why Building Software Is Like Building a House (And Why Most People Underestimate the Process)
2026-04-14 | AI / LLM
Why Your Corporate Data Isn’t Safe in AI (And What to Do About It)

Martin Jurek
CEO, Inogile
2026-04-01 | Information Systems | INOGILE
Why Building Software Is Like Building a House (And Why Most People Underestimate the Process)
Martin Jurek
CEO, Inogile

2026-01-16 | INOGILE
Networking and personal meetings as the foundation of business
Martin Jurek
CEO, Inogile

2025-11-24 | INOGILE | AI / LLM
Interview with our CEO for the Startitup portal
Martin Jurek
CEO, Inogile

2025-04-15 | AI / LLM
Overview of AI Tools for Streamlining Work
Martin Jurek
CEO, Inogile

2025-04-12 | AI / LLM | Information Systems | Mobile Applications
What is vibecoding – and why it 'doesn’t work'
Martin Jurek
CEO, Inogile

2025-04-10 | INOGILE
Summer Company Event 2025 / When Programmers Hit the Ranch
Martin Jurek
CEO, Inogile
2024-12-20 | INOGILE
INOGILE / Starbug is expanding into the Czech Republic
Martin Jurek
CEO, Inogile






