Proč vaše firemní data nejsou v AI v bezpečí (a co s tím)

Proč váš chatbot potřebuje vlastní domov
Dnes je všechno AI. AI mixér, AI toaletní papír, dokonce i AI protein. Pokud váš produkt nemá v názvu tato dvě písmena, jako by ani neexistoval.
Ale zatímco se svět veze na vlně hypu, my v Inogile (ano, dříve jsme byli ti „Starbug kluci“) jsme se podívali pod kapotu. A řeknu vám — není to vždy pěkný pohled.
Možná mě znáte jako člověka, který se nebojí říkat věci na rovinu. Takže tady je krutá pravda: Vaše firemní tajemství jsou pravděpodobně právě teď tréninkovým materiálem pro Google nebo OpenAI.
Jsou dnešní modely bezpečné? Spoiler: Ne.
Když jsem si četl Privacy Policy pro Gemini, málem jsem se zakuckal kávou. Google tam černé na bílém píše: „Nezadávejte důvěrné informace.“ Proč? Protože je vidí kontrolor, Google je používá k učení a zítra je váš konkurent může dostat jako odpověď na svůj prompt.
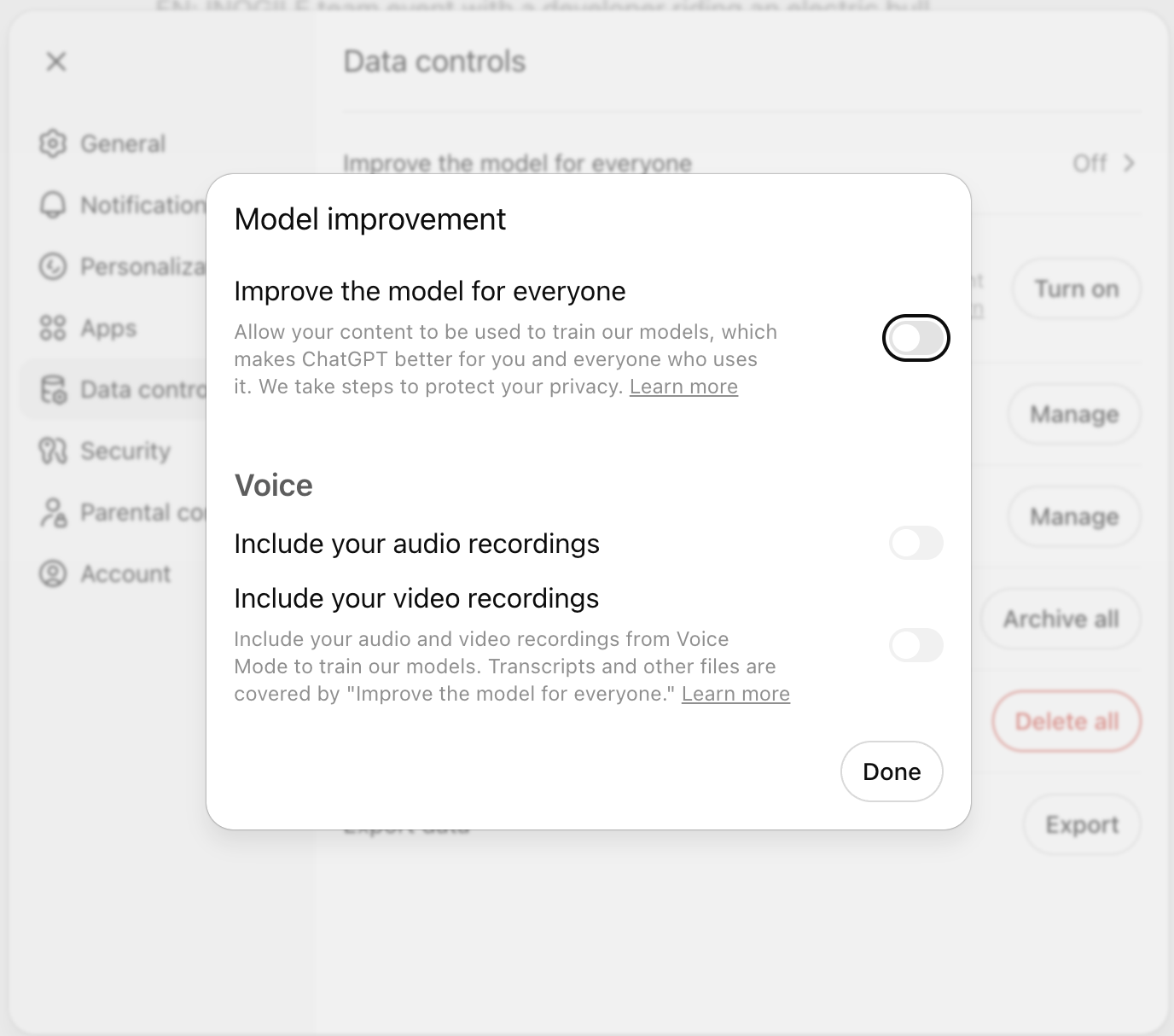
Podobné podmínky používání najdete i u konkurenčního ChatGPT, který rovněž uvádí, že používá data ke strojovému učení. Novinkou je, že se můžete z tohoto učení odhlásit a přímo v nastavení si danou funkci vypnout. Zda reálné vypnutí této funkce zajistí, že vaše data nebudou sdílena — to nechávám na zodpovědnosti každého z vás.
Minimálně doporučuji nastavit následující nastavení v GPT (spíše pro dobrý pocit bezpečí):
Reálné „milionové průšvihy“
A není to jen teorie. Máme tu reálné případy, které stály firmy miliony:
Samsung (2023)
Zaměstnanci Samsung Semiconductor vložili do ChatGPT zdrojový kód z databáze čipů, kód na optimalizaci defektních zařízení a přepis interního meetingu — tři samostatné incidenty za 20 dní. Výsledek? Všechna tato data se stala součástí tréninkových dat OpenAI. Samsung to už nedokázal vzít zpět — data jsou na serverech OpenAI a podle jejich vlastních slov je nedokážou vymazat z konkrétních promptů.
Samsung po tomto incidentu omezil vstupy do ChatGPT na 1 024 bajtů a začal vyvíjet vlastní interní AI nástroj (Gauss). V roce 2025 uvolnil přístup k ChatGPT s novými bezpečnostními protokoly.
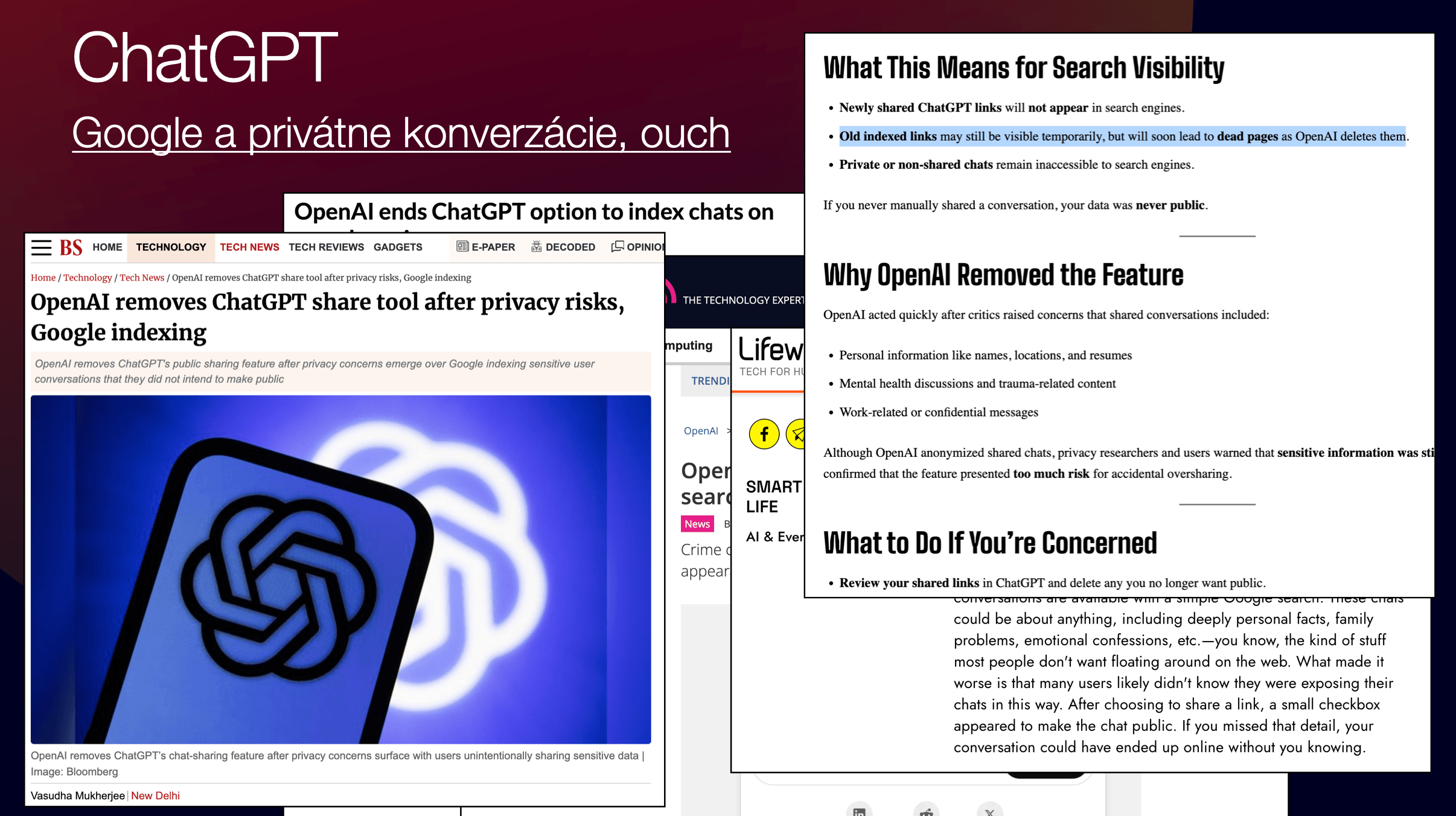
Konverzace z ChatGPT na Googlu (2025)
V létě 2025 se ukázalo, že sdílené konverzace z ChatGPT byly indexovány přímo ve vyhledávání Google. Stačilo do Googlu napsat site:chatgpt.com/share a mohli jste najít životopisy s plnými jmény a telefonními čísly, firemní strategie, API klíče, dokonce i osobní vyznání.
Jak se to stalo? ChatGPT měl funkci „Share“ se zaškrtávacím políčkem „Make this chat discoverable.“ Problém byl v tom, že robots.txt OpenAI povoloval indexaci těchto stránek a chyběly noindex tagy. Takže Google udělal to, co dělá vždy — zaindexoval vše, co mohl. Odhaduje se, že bylo zaindexováno více než 100 000 konverzací.
OpenAI funkci nakonec zrušil a požádal Google o deindexaci. Ale mnohé konverzace jsou stále dostupné na Archive.org. Navždy.

Řešení? Postavte si vlastního agenta. Na vlastním železe.
Zákazník nechce slyšet, že jeho data jsou „možná“ v bezpečí. Chce mít jistotu. Proto v Inogile razíme cestu offline AI agentů.
Co k tomu potřebujete?
1. Pořádný počítač: Zapomeňte na předražené workstations. Nejlepší poměr cena/výkon pro běh LLM má dnes Mac Mini s Apple Silicon. Díky sdílené paměti (unified memory) funguje excelentně — GPU a CPU sdílejí stejný paměťový prostor, což je přesně to, co LLM modely potřebují.
2. Přehrávač — Ollama: Představte si to jako Winamp pro umělou inteligenci. Stáhnete si model (například Llama od Meta nebo Mistral) a spustíte ho u sebe. Bez internetu. Vaše data nikdy neopustí vaši budovu.
3. Python: Trochu kódování, které to celé spojí do funkčního celku.
Svatý grál: Naučte model vaše data
Známe několik typů učení modelů. Jedním je SFT (Supervised Fine Tuning) — plnohodnotné dotrénování modelu na vašich datech. Je to výkonné, ale drahé a časově náročné. Pro mnoho případů existuje jednodušší cesta: RAG (Retrieval-Augmented Generation).
RAG je v podstatě „obalovač“ otázek. Představte si, že máte model, který ví věci jen do roku 2023. Je to takový malý hloupý génius v krabici. Když se ho zeptáte na vaši firmu, neví nic.
Ale pokud mezi vás a AI vložíte RAG vrstvu, ta vezme vaši otázku, přidá k ní aktuální data (například vaše obchodní podmínky nebo produktový katalog) a předhodí to modelu s instrukcí: „Odpověz na toto, ale použij pouze tento kontext.“
Výsledek? Máte chatbota, který zná vaše nejnovější produkty, ale vaše data nikdy neopustí budovu.
Důležité je vědět, že RAG není zázrak. RAG obalovač otázek také čerpá tokeny, které model dokáže zpracovat. Čím více dat je obsaženo v RAG souboru, tím méně prostoru zbývá modelu na samotnou odpověď. Pro komplikovanější případy — velký objem dat, složité struktury — se firma nevyhne plnohodnotnému učení přes SFT.
Personalizace: Od seniora po generaci Alfa
Krása vlastního orchestrátoru (to jste vy — takový Tony Stark vaší AI) spočívá v tom, že si můžete vyladit chování:
• Chcete, aby AI odpovídala právníkovi? Použije odbornou terminologii a přesné formulace.
• Chcete odpověď pro 12letého „hobita“ z generace Alfa? RAG mu řekne, že váš produkt je „OMG fr úplně topka.“
Ano, umělá inteligence se ráda „rozpovídá“, protože z vás chce vytáhnout tokeny (za které se v cloudu platí). Ale ve vlastním systému jí jednoduše přikážete: „Buď stručná a nedělej ze mě hlupáka.“ A ona poslechne.
Verdikt: Potřebujete na to IT firmu?
Asi mě teď podezříváte z narcismu, ale odpověď zní: ano.
Jasné, RAG soubor si vygenerujete i sami přes ChatGPT (pokud vám nevadí, že se na vás zase učí). Ale postavit robustní systém, kde nic nehoří, databáze fungují a zákazník má reálnou hodnotu — to je už jiná liga.
RAG je skvělý pomocník, ale stále je třeba ho brát spíše jako efektivní nástroj na zlepšení produktivity, ne jako náhradu plnohodnotného AI řešení. Pro komplikovanější scénáře je SFT nezbytné.
Budoucnost není v tom, kdo má větší předplatné v OpenAI. Budoucnost je v tom, kdo dokáže AI zkrotit, zabezpečit a přimět ji pracovat na vlastních datech. My v Inogile to už děláme.
Máte odvahu odpojit se od cloudu a začít opravdu vlastnit svou inteligenci?
Zastavte se u nás, otestujeme vás.
Další články


INOGILE / Starbug expanduje do České republiky
Proč je vývoj softwaru jako stavba domu (a proč většina lidí tu stavbu podcení)
2026-04-14 | Umělá inteligence
Proč vaše firemní data nejsou v AI v bezpečí (a co s tím)

Martin Jurek
CEO, Inogile
2026-04-01 | Informační systémy | INOGILE
Proč je vývoj softwaru jako stavba domu (a proč většina lidí tu stavbu podcení)
Martin Jurek
CEO, Inogile

2026-01-16 | INOGILE
Networking a osobní setkání jako základní kámen obchodu
Martin Jurek
CEO, Inogile

2025-11-24 | INOGILE | Umělá inteligence
Rozhovor s naším CEO pro portál Startitup
Martin Jurek
CEO, Inogile

2025-04-15 | Umělá inteligence
Přehled AI nástrojů pro zefektivnění práce
Martin Jurek
CEO, Inogile

2025-04-12 | Umělá inteligence | Informační systémy | Mobilní aplikace
Co je vibecoding – proč to „nefunguje“
Martin Jurek
CEO, Inogile

2025-04-10 | INOGILE
Letní firemní akce 2025 / Když se programátoři dostanou na ranč
Martin Jurek
CEO, Inogile
2024-12-20 | INOGILE
INOGILE / Starbug expanduje do České republiky
Martin Jurek
CEO, Inogile






